

فولکسونومی – folk – Taxonomy – folksonomy
فولکسونومی – folk – Taxonomy – folksonomy
مقدمه
فولکسونومی رویکردی جدید به سازماندهی محتوای وب است. این اصطلاح به نوعی رده بندی اطلاق می شود که از سوی عامه کاربران اجرا می شود و تابع قوانین علمی خاصی نیست ما مبنای فلسفی خاص خود را داراست. کاربر طی این روند اطلاعاتی را که در اشکال مختلف در وب به دست می آورد، با استفاده از کلیدواژه هایی که در اصطلاح فولکسونومی«تگ» یا برچسب نامیده میشوند، طبقهبندی کرده،و با دیگر کاربران به اشتراک میگذارد (کریم زاده، 1387، ص24).
تاریخچه
عبارت فولکسونومی در سال 2005 هنگامی که معمار اطلاعات،توماس وندروال، واژگان folk وtaxonomy را برای نامگذاری پدیده در حال رشد ابرداده های تولیدشده از سوی کاربران، از طریق برچسبگذاری قطعات اطلاعات دیجیتالی با کلمات کلیدی قابل جستوجوی خود، با یکدیگر ترکیب کرد، شکل گرفت (کریم زاده، 1387، ص25).
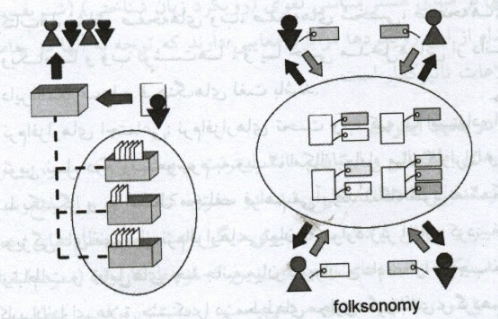
فولکسونومی – folk – Taxonomy
اهداف فولکسونومی
– ذخیرهسازی و به اشتراک گذاشتن پیوندها به سادهترین شکل ممکن.
– به کاربران اجازه میدهد که به راحتی پیوندها(منابع وب)را با همهء کاربران دیگر در دنیا به اشتراک گذارند.
مزایای فولکسونومی
– شناسایی علایق کاربران: فهرست تگهای کاربران میتواند توصیفی از علایق را بررسی کند.فهرست تگهای کاربران در طول زمان افزایش مییابد،به طوری که آنها علایق جدید و تگهای جدید برای طبقهبندی و توصیف آنها کشف میکنند. ممکن است که تگ تازه ایجاد شده یک علاقه یا طبقهء جدید از کاربر را نشان دهد(نوروزی، منصوری، 1385)
– تاثیرگذاری در بازیابی محتوا، به دلیل مفاهیم به کار رفته با زبان کاربران (بابائی، 1390)
– فولکسونومی ها را می توان به عنوان یک سیستم دموکراتیک شناخت، زیرا هرکسی فرصت به اشتراکگذاری تگها را دارد. (کریم زاده، 1387، ص27).
محدودیت های فولکسونومی
احتمالا نقیصه اصلی سیستمهای کنونی فولکسونومی این باشد که عبارات برچسبگذاری مورد استفاده در این سیستمها غیر دقیق است. در حال حاضر کنترل کمی روی واژگان هم معنا (واژگان مختلف، معانی یکسان) و لغات متشابه (واژگانی با تلفظ یکسان و معانی متفاوت) وجود دارد. مدیران سیستم دربارهء برچسبهای انتخاب شده از سوی کاربران قضاوت نمیکنند. همچنین برچسبهای اختصاصی و نامفهوم که به عنوان نشانگرهای منحصربهفرد بین گروهی از دوستان و همکاران طرح میشود، ممکن است به کار گرفته شوند .نتیجه این امر ایجاد مجموعهای کنترلنشده و بیقاعده از عبارات برچسبگذاری میگردد که مانند گروههای بیشتر کنترلشده لغات، از قابلیت جستوجوی کارآمدی پشتیبانی نمی کند. (کریم زاده، 1387، ص27). فوکسونومی، هیچ مکانیزمی برای پیشگیری از انتخاب واژهها توسط کاربر ندارد، حتی هنگامی که دیگران به کاربرد آن واژه حساس باشند (بابائی، 1390).
بنابراین می توان محدودیت های موجود در فولکسونومی را در موارد زیر خلاصه کرد:
– فقدان استانداردهای پذیرفته شده
– عدم محدودیت کاربر در استفاده از برچسب ها
– مشکلات لغوی و معنایی
– دقت
– ابهام
– مترادف ها
– متضادها
– متشابه ها
– اخص و اعم
– ترکیبات
– ایرادات معنایی و لغوی (اسماعیل زاده، ملک آبادی زاده، 1388)
عناصر فولکسونومی
– کاربر: هر شخصی با هر دانشی که از منابع وب با هر هدفی استفاده می کند.
– برچسب: هر نوع کلیدواژه ای که با هر شکل و ساختاری برای توصیف یک عنصر اطلاعاتی، توسط کاربر انتخاب می شود.
– اطلاعات: هر نوع داده ای که با هر شکل و ساختار و در هر موضوعی در وب منتشر شده باشد.
– نرم افزارهای اجتماعی: نرم افزارهای تحت وب که با استفاده از فناوری نوین نسل دوم وب موسوم به وب ۲، امکان تعامل کاربران و داده ها را با یکدیگر، به اشکال مختلف فراهم آورده اند. (حسینی، 1386)
روند گردش اطلاعات در فولکسونومی
مرحله اول : برچسب گذاری صفحات وب، نشانی های اینترنتی ، فایلهای صوتی و تصویری، اسناد متنی و … .
مرحله دوم: اشتراک برچسب های ایجاد شده در راهنماهای وبی ویژه فولکسونومی مانند فلیکر
مرحله سوم: بازیابی برچسب ها توسط سیستم جستجوی کلیدواژه ای، فهرست الفبایی برچسبها، فهرست برچسب های مهم و فهرست موضوعی (حسینی، 1386) .
روش های بهبود عملکرد فولکسونومی
مهم ترین مورد بهبود خوانایی برچسب هاست. بهبود خوانایی برچسبها در دنیای فولکسونومی با دو روش امکانپذیر است. نخست اینکه لازم است جامعه برای ایجاد مجموعهای از قوانین و رسیدن به توافقی روی یک مجموعه استاندارد برای برچسبها آماده شود. دوم اینکه کاربران باید با این قوانین آشنا شده و از آن پیروی کنند (کریم زاده، 1387، ص 31).
نتیجه گیری
فولکسونومی، با ایجاد رابطه تعاملی چندگانه بین داده و کاربر، علاوه بر ساده کردن روند سازماندهی محتوای وب، امکان بازیابی و اشاعه اطلاعات را نیز برای همه کاربران به آسانی فرآهم آورده است و ضمن اینکه امکان تعامل های فکری و تبادل دانش و اندیشه بین کاربران را با بهره گیری از کلیدواژه هایی ساده، میسر نموده است، می تواند به ابزاری برای سنجش علائق کاربران وب تبدیل شود. با این حال سازماندهی منابع اینترنت، همیشه در بین کتابداران و متخصصان علوم اطلاع رسانی با چالش هایی مواجه بوده است و فولکسونومی نیز، به این چالش اضافه شده است. گرچه فولکسونومی توانسته است تا حدودی چشم انداز روشنی از رده بندی محتوای وب ارائه دهد، اما تا زمانی که قواعد واستانداردهایی خاص برای این منظور تدوین نگردد، بحث ساماندهی اطلاعات وبی همچنان ادامه خواهد داشت. (حسینی، 1386)
اسماعیل زاده، ربابه، ملک آبادی زاده، فاطمه (1388). “آشنایی با رده بندی مردمی محتوای وب (فوکسونومی)”. نشریه الکترونیکی انجمن کتابداری و اطلاع رسانی ایران (شاخه خراسان(، شماره اول. بازیابی 27/8/1390 قابل دسترس در:
http://ilisa-khorasan.ir/index.php?option=com_content&view=article&id=249:1388-07-23-08-42-49&catid=87:1388-06-25-10-34-31&Itemid=95
بابائی، محمود (1390). “درباره فوکسونومی: رده بندی مردمی”. بازیابی 27/8/1390 قابل دسترس در:
http://cyber-notes.blogsky.com/1390/02/05/post-3
حسینی، سیدمهدی (۱۳۸۵). “فوکسونومی: رویکردی نوین به سازماندهی منابع اطلاعاتی وب”. ارائه شده در: همایش راهبردها و راهکارهای نوین در سازماندهی اطلاعات، کتابخانه ملی ایران، ۱۶ و ۱۷ اسفندماه ۱۳۸۵.
کریم زاده، سارا (1387). “فولکسونومی چیست”. کتاب ماه کلیات، شماره 130، مهر 1387.
نوروزی، علیرضا؛ منصوری، علی (۱۳۸۵). “ردهبندی مردمی (فوکسونومی) در تقابل با نظامهای ردهبندی کتابخانهای”. ارائه شده در: همایش راهبردها و راهکارهای نوین در سازماندهی اطلاعات، کتابخانه ملی ایران، ۱۶ و ۱۷ اسفندماه ۱۳۸۵
صابر فضلی احمدی

SABER FAZLI AHMADI صابر فضلی احمدی
فارغ التحصیل مهندسی برق کنترل از دانشگاه آزاد اسلامی قزوین و فارغ التحصیل فوق لیسانس مدیریت فناوری اطلاعات – سیستم های اطلاعاتی دانشگاه آزاد واحد علوم و تحقیقات تهران در سال 1394 می باشد.
در دوره ی کارشناسی با داده کاوی و علم داده آشنا شد و حاصل آن پایان نامه ای در مقطع کارشناسی ارشد با عنوان “کاربرد داده کاوی و هوش مصنوعی در سیستم های مدیریت محتوا” بود.
علایق کاری وی: علم داده، برنامه نویسی به زبان های مختلف، تحلیل سیستم، مدیریت پروژه، تکنولوژی های نوین، دست و پنجه نرم کردن با چالش های جدید.
لینک نمونه کارهای انجام شده صابر فضلی احمدی مرتبط با Data Analytic – تحلیل داده :
Data Analytic – تحلیل داده > تحلیل توصیفی > داشبوردها
http://rayantabib.com/data_analytic/
آدرس ایمیل شخصی صابر فضلی احمدی :
info@rayantabib.com
لینک دانلود رزومه صابر فضلی احمدی :
http://saberfazliahmadi.ir/wp-content/uploads/2016/05/English-Resume-Saber-Fazli-Ahmadi.pdf
برچسب های قدرتمند در فولکسونومی: ابزاری برای سازماندهی دانش
مقدمه
سازماندهی دانش یکی از ارکان اصلی علم اطلاعات و دانش شناسی است این امر در محیط وب که روزانه حجم عظیمی از اطلاعات منتشر می شود، از نظردسترسی سریع کاربران به اطلاعات مورد نیازشان ضروری – تر شده است. «گه گاه جست و جوی منابع در محیط وب مستلزم صرف وقت زیادی است و بعضا شبیه جست و جوی سوزن در خرمن کاهی می باشد، تشدید جریان اطلاعات در جوامع اضافه بار اطلاعاتی را پدید می آورد.» (داورپناه، 1391)
تاکنون تلاش های زیادی برای سازماندهی منابع وب انجام شده است که استفاده از طرح های رده بندی برای سازماندهی منابع وب، ایجاد راهنماهای وبی[1]،ابر داده ها[2] و فولکسونومی ها[3] نمونه هایی این امر می باشد.
در ابتدای امر سازماندهی منابع وب با استفاده از فناوریهای وب1 که در آن تنها کاربران مصرف کننده بودند، انجام می شد اما به تدریج درگاه جدیدی از وب به نام وب2 متولد شد و کتابداران از قابلیت های وب2 برای سازمان دهی دانش استفاده کردند. وب2 که با مفهوم نرم افزارهای اجتماعی معنا پیدا می کند تاثیرات شگرفی را بر تعامل کاربران با دنیای اینترنت نهاده است به گونه ای که آن ها تمایل بیشتری به انتشار محتوا در اینترنت پیدا کرده اند و نظرات شخصی، عکس ها،فیلم ها و دانش شخصی خود را به اشتراک می گذارند.
نکته مهم در فولکسونومی ها که یکی از نمونه های بارز استفاده از رویکردهای کاربرمحور در امر سازماندهی دانش است، برچسب گذاری از سوی کاربران می باشد. «طی این روند کاربر اطلاعاتی را که به اشکال مختلف از از وب به دست می آورد با استفاده از کلید واژه هایی که که در اصطلاح برچسب4 نامیده می شود طبقه بندی کرده و اطلاعات آن ها را در راهنماهای ویژه ای که با استفاده از نرم افزارهای اجتماعی مدیریت می شوند وارد می نماید. بدین ترتیب هر کاربر می تواند برچسب های مورد علاقه خود را گرد آوری کند، آن ها را به اشتراک بگذارد و از علایق دیگر کاربران آگاهی یابد». (مردانی،88) از میان برچسب های اختصاص داده شده کاربران در رده بندیهای مردم برچسب های قدرتمند[5] مهمترین برچسب به شمار می روند.
این نوع برچسب در واقع حاکی از نوعی فهم جمعی یا اتفاق نظر عمومی می باشد که برهمین اساس می تواند به منزله عنصری مهم جهت سازماندهی مورد استفاده قرار گیرد.
تشخیص اینکه کاربران عموما از چه کلید واژه هایی برای برچسب گذاری و نمایه سازی منابع به اشتراک گذاری شده خود در رده بندی های مردمی استفاده می کنند به وسیله برچسب قدرتمند انجام می شود به همین جهت برچسب قدرتمند منعکس کننده فهم جمعی کاربران در امر سازماندهی دانش می باشد.
نوشتار حاضر قصد دارد ابتدا تعریف و انواع فولکسونومی ها را به بحث بگذارد و پس از تعریف برچسب قدرتمند چگونگی سازماندهی دانش را به وسیله آن مورد بررسی قرار دهد.
عبارت فولکسونومی برای اولین بار در سال 2005 توسط توماس وندرال معمار اطلاعات استفاده شد، این واژه از واژگان folk به معنای مردم و taxonomy به معنای رده بندی تشکیل شده است.
« یک رده بندی تولید شده از سوی کاربر است که برای طبقه بندی و بازیابی محتوای وب مانند منابع وب تصاویر پیوسته اتصالات وب و برچسب هایی با انتهای باز که تگ نامیده می شود به کار می رود.»(کریم زاده 87).
توماس وندرال سه جزء مهم را در رده بندی های مردمی برمی شمارد:
کاربران: هرشخصی با هر دانشی که از منابع وب با هر هدفی استفاده می کند. کاربر می تواند پدیدآورنده اطلاعات و دادها باشد یا صرفا آن ها را در منابع وب بازیابی کند.
منابع توصیف شده به وسیله یک شناساگر واحد نظیر url یا ISBN
توصیفگرها یا برچسب های به کار رفته برای توصیف منابع اطلاعاتی
برخی از مهم ترین فولکسونومی ها
در زیر آدرس اینترنتی برخی از مهم ترین فولکسونومی ها آمده است:
www.del.cio.us.com
www.citeulike.org
www.connote.org
www.flickr.com
www.furl.net
www.librarything.com
www.scuttle.org
www.shadows.com
www.simpy.com
www.tagcloud.com
www.tagzania.com
www.Technorati.com
www.unalog.com
www.myweb.yahoo.com
www.youtube.com
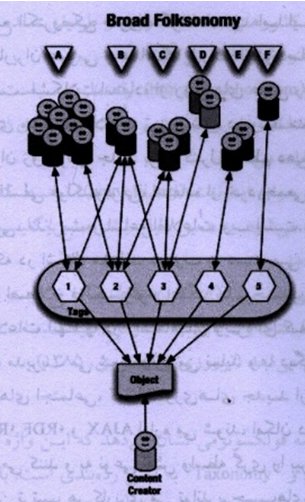
فولکسونومی های وسیع و محدود
فولکسونومیها ممکن است اجازه اختصاص چندین تگ منحصر به فرد را به یک منبع مشخص بدهند. بنابراین ما می توانیم در این مورد از فولکسونومیهای وسیع صحبت کنیم. در مقابل این فولکسونومیهای محدود تنها اجازه اضافه کردن برچسب های جدید را به منابع می دهند. مثال نمونه برای فولکسونومیهای وسیع و محدود دلیشز و یوتیوب می باشد. تفاوت اصلی بین فولکسونومی های وسیع و محدود این است که در فولکسونومی های وسیع توزیع فراوانی برچسب در سطح منبع قابل مشاهده است.(petrs,2010)
برچسب و برچسب گذاری
« برچسب بسته اطلاعاتی کوچکی است که در قالب یک بیان لغوی میان جمعی از متخصصان یا غیر متخصصان برای توصیف پاره ای از ویژگیهای مشخص قبول عام یافته است».(ارسطوپور؛ آزاد،86)
به عبارت دیگر برچسب ها واژگان یا عباراتی هستند که به صفحات وب پیوست می خورند و صرفاً برای منابع وبی اند که برای کمک به کاربر در بازیابی های منابع وب در آینده به کارمی روند. هیچ مجموعه ثابتی از دسته ها یا گزینش اثبات شده وجود ندارد. کاربر می تواند واژگان، نام های مخفف یا اعداد را بدون توجه به نیاز یا خواست دیگران، برای توصیف منابع وب به کاربرد.
« برچسب گذاری اجزای واژگانی فرآیند انتساب دادن اجزای کلام یا واحد زبانی مناسب (فعل , اسم…) به هر کلمه در یک جمله زبان طبیعی می باشد. برچسب گذاری یک بخش مهم در پردازش زبان طبیعی می باشد و برای بسیاری از کاربرد های پردازش زبان سودمند است».(خوشحال، 93)
بنابراین برچسب گذاری فرایندی است که در آن کلیدواژگان (برچسب ها) به شکل دستی به منابع تخصیص می یابند تا بازیابی شان آسان باشد.
در مقابل نمایه سازی موضوعی سنتی، کلیدواژگان عموماً آزادانه از سوی کاربر گزینش شده و در جامعه به اشتراک گذاشته می شوند. خروجی فعالیت ها در نظام برچسب گذاری، رده بندی عامه (Folksonomy) خوانده می شود.
برچسب های قدرتمند
برچسب های قدرتمند در سیستم های نشانه گذاری اجتماعی مانند فولکسونومی ها ابزاری مهم و اساسی جهت سازماندهی منابع به حساب می آیند.
به برچسب هایی که از سوی کاربران بسیار تکرار می شوند (high-frequent tags ، بسیار محبوب هستندmost popular) و نوعی اتفاق نظر ضمنی(implicit (consensus یا فهم جمعی (collective intelligence) را منتقل می کنند، برچسب قدرتمند می گویند.1[3]
هراندازه که کاربران بیشتری بر روی استفاده از برچسبی برای منبعی اتفاق نظر بیشتری داشته باشند، به عبارت دیگر هر اندازه فراوانی برچسبی خاص برای منبعی بیشتر شود آن برچسب های قدرتمند به صورت پررنگ تر و با فونتی بزرگ تر نسبت به سایر برچسب های موجود در فولکسونومی نمایش داده می شوند.2
سازماندهی دانش به وسیله برچسب های قدرتمند
تعیین برچسب یا برچسبهای قدرتمند در فولکسونومی
جهت تعیین برچسب قدرتمند در ابتدا توزیع فراوانی برچسب ها را در فولکسونومی مشخص می کنیم و در نمودارتوزیع فراوانی برچسب ها به ترتیب فراوانی آنها از بالا به پایین مرتب می کنیم. در صورتی که فراوانی برچسب رتبه اول با فراوانی برچسب رتبه دوم فاصله زیادی داشت و هم چنین تعداد کمی از برچسب های دارای فراوانی زیاد در سمت چپ نمودار و متقابلا تعداد زیادی از برچسب های دارای فراوانی کم در سمت راست نمودار ظاهر شود اولین برچسب یا همان برچسب رتبه اول به عنوان برچسب قدرتمند شناخته می شود.
اما در صورتی که تعداد زیادی از برچسب های دارای فراوانی بالا در سمت چپ نمودار توزیع فراوانی و تعداد کمی از برچسب های دارای فراوانی کم در سمت راست نمودار توزیع فراوانی ظاهر شدند در آن صوررت بیش از یک عدد برچسب قدرتمند خواهیم داشت و همه برچسب های بالای خمیدگی در نمودار به عنوان برچسب قدرتمند شناخته می شوند.
برای مثال کاربران برای منبعی با عنوان «مخترع اندروید» در فولکسونومی delicious برچسب های «گوگل»، «اندروید»، «توسعه» و… را اختصاص داده اند، بنابراین نمودار توزیع فراوانی آن به این شکل خواهد بود:
با توجه به نمودار ترسیم شده که تعداد کمی از برچسب های با فراوانی بالا در سمت چپ نمودار هستند و تعداد زیادی از برچسب های با فراوانی پایین در سمت راست قرار دارند و هم چنین اختلاف فراوانی های برچسب اول و دوم نیز زیاد است بنابراین اولین برچسب دارای فراوانی بالا به عنوان برچسب قدرتمند انتخاب می شود. بنابراین مرحله اول یعنی تعیین برچسب یا برچسب های قدرتمند به پایان می رسد و برچسب اندروید به عنوان برچسب قدرتمند برای منبعی با عنوان مخترع اندروید انتخاب می گردد.
تعیین برچسب یا برچسب های قدرتمند جفتی
پس از تعیین برچسب قدرتمند مرحله بعد تعیین برچسب یا برچسب های قدرتمند جفتی می باشد. به همین منظور فراوانی رخداد[4]1برچسب قدرتمند تعیین شده (اندروید) با سایر برچسب ها در delcious اندازه گیری می شود. به عبارت دیگر این نکته که برچسب اندروید با کدام یک از برچسب های دیگر در delicious بیشتر همراه می شود تعیین می شود. در این مورد نمودار توزیع فراوانی رخداد برچسب قدرتمند اندروید با برچسب های دیگر جهت تعیین برچسب یا برچسب های قدرتمند جفتی رسم می گردد. بار دیگر در صورتی که فراوانی برچسب رتبه اول با فراوانی برچسب رتبه دوم فاصله زیادی داشت و هم چنین تعداد کمی از برچسب های دارای فراوانی زیاد در سمت چپ نمودار و متقابلا تعداد زیادی از برچسب های دارای فراوانی کم در سمت راست نمودار ظاهر شد اولین برچسب به همان برچسب رتبه اول به عنوان برچسب قدرتمند شناخته می شود. اما در صورتی که تعداد زیادی از برچسب های دارای فراوانی بالا در سمت چپ نمودار توزیع فراوانی و تعداد کمی از برچسب های دارای فراوانی کم در سمت راست نمودار توزیع فراوانی ظاهر شدند در آن صوررت بیش از یک عدد برچسب قدرتمند خواهیم داشت و همه برچسب های بالای خمیدگی در نمودار به عنوان برچسب قدرتمند شناخته می شوند. نمودار فراوانی رخداد برچسب قدرتمند اندروید با سایر برچسب ها در delicious به این شکل است:
با توجه به اینکه در نمودار ترسیم شده برخلاف نمودار توزیع فراوانی برچسب قدرتمند که تعداد زیادی از برچسب های فراوانی بالا با برچسب اندروید در سمت چپ قرار دارند و تعداد کمی از برچسب های دارای فراوانی کم در سمت راست هستند همه برچسبهای بالای منحنی خمیدگی یعنی mobile, google, iPhone, development, apps, software به عنوان برچسبهای قدرتمند جفتی با برچسب اندروید انتخاب می شود. بنابراین کلیه برچسب های قدرتمند جفتی با برچسب قدرتمند اندروید اصطلاح مرتبط هستند. البته بدیهی است که ساختن یک سیستم سازماندهی با استفاده از برچسب های قدرتمند تا حدودی مستلزم تحلیل های ذهنی انسان مدارانه نیز می باشد. با توجه به برچسب قدرتمند اندروید و برچسب های قدرتمند جفتی یک سیستم سازماندهی برای منبعی با عنوان «مخترع اندروید» می تواند به این شکل پایه ریزی شود:
اندروید
ا.ع. تلفن
ا.ع. نرم افزار
ا.و. موبایل
ا.و. گوگل
ا.و. آی فون
ا.و. توسعه
ا.و. آپ
نظر به اینکه عمل برچسب گذاری به وسلیه زبان طبیعی کاربران انجام می شود، بنابراین همه مزایا و معایب زبان طبیعی هم در مورد آن صادق می باشد. باتوجه به این نکته برخی ها براین باورند که برچسب ها آن گونه که در رده بندی های مردمی نمایه سازی می شوند قابل استفاده نیستند. دراین صورت جهت حل مشکل برچسب گذاری به زبان طبیعی می توان از برچسب های اختصاص داده شده کاربران جهت خلق اصطلاحنامه مردمی استفاده کرد یعنی ساخت ابزار سازماندهی دانشی که با ستفاده از خردجمعی مردم تدوین شده است. روشی که در بالا به آن اشاره شد می تواند جهت نیل به مقصود در این زمینه مفید باشد. به خدمت گیری اصطلاحنامه های مردمی هم می تواند به بهبود برچسب ها در فولکسونومی و جلوگیری از توزیع نامناسب واژگان در چنین نظامی کمک کند.
نتیجه گیری
تاکنون تلاشهای زیادی جهت سازماندهی وب انجام شده است، این کوشش ها در ابتدای امر تحت امکانات وب1 بود یعنی کاربران تنها به عنوان مصرف کننده صرف منابع به اطلاعاتی وب بودند وهیچ گونه نقشی در به اشتراک گذاری و سازماندهی منابع وب نداشتند، اما از زمانی که رویکرد جدیدی از وب به نام وب2 ایجاد شد و هم چنین با رواج دیگاه های کاربرمحور در امر سازماندهی از امکانات و قابلیت های وب2 برای سازماندهی دانش استفاده شد. یکی از نمونه های استفاده از امکانات وب2 جهت سازماندهی دانش فولکسونومی ها می باشد که در نتیجه عمل برچسب گذاری منابع به اشتراک گذاری شده توسط کاربران به وجود می آید. یعنی کاربران هم خود منابع را به اشتراک می گذارند و هم به سازماندهی منابع وب از طریق اختصاص برچسب عمل می کنند. برای رفع برخی از مشکلات برچسب گذاری به شیوه جمعی که زبان طبیعی استفاده می کند می توان از نوعی از برچسب ها موسوم به برچسب قدرتمند جهت ساخت اصطلاحنامه مردمی استفاده کرد( همان گونه که در متن توضیح داده شد) تا بدین وسیله کیفیت برچسب ها را ارتقا داد و با بخشی از مشکلات سازماندهی به زبان طبیعی مقابله کرد.
منابع
ارسطوپور، شعله؛ آزاد، اسدالله. (نظریه برچسب گذاری و برچسب های موضوعی در سازماندهی اطلاعات نگاهی تطبیقی از زاویه ارتباط های متقاعدگرایانه) مجله کتابداری و اطلاع رسانی. زمستان 1386. شماره 40. ص. 40-30.
خوشحال، مصطفی. ( ارائه یک سیستم برچسب گذاری خودکار اجزای واژگانی کلام برای متون فارسی (پایان نامه ارشد)). 1393.
داورپناه، محمدرضا. (اطلاعات و جامعه). تهران: چاپار: دبیزش، 1391. ص. 89.
کریم زاده، سارا. ( فولکسونومی چیست؟). کتاب ماه کلیات شماره 130. مهر 1387. ص. 33-24
مردانی، امیرحسین. (فولکسونومی: از آن کاربران، برای کاربران) فصلنامه کتاب. شماره 79.پاییز 1388. ص. 260-239.
6.peters,Isabella. (power tags as tools for social knowledge organization systems). Researchgate publication. 2010
1. directory
2. Metadata
3. folksonomy
4. tag
5. power tags
این تعریف براساس مقاله Isabella petrs منبع شماره 6 در بخش منابع ارائه شده البته لازم به ذکر است که در مفاهیم به کار برده شده به صورت تلویحی از بخشهای مختلف مقاله به وسیله نگارنده استنباط شده است و در اصل مقاله مبحثی به تعریف برچسب قدرتمند اختصاص داده نشده بود. هم چنین جست و جو در منابع فارسی نیز در مورد برچسب قدرتمند نتیجه ی قابل ذکری در بر نداشت.
جهت مشاهده مثال در این زمینه می توانید به فولکسونومی librarythin مراجعه نمایید. از طریق لینک ذیل:
blog.librarything.com/main/2007/08/tag-mirror-see-your-books-the-way-others-do
مطالب این بخش اقتباسی از مقاله Isabella petrs منبع شماره 6 به همراه تغییرات توسط نگارنده می باشد.
co-occurrences
فولکسونومی چیست؟
فولکسونومی (رده بندی مردمی)
سازماندهی اطلاعات (گردآوری، ذخیره و پردازشی) به منظور تسهیل فرایند بازیابی اطلاعات مناسب در کوتاهترین زمان ممکن، همواره یکی از مهم ترین مسائل و مباحث در حوزه کتابداری و اطلاع رسانی بوده است که امروزه با ورود فناوری های اطلاعاتی و ارتباطی نوین مانند اینترنت و وب دستخوش تغییر و چالش شده است. یکی از جلوههای شناخته شده سازماندهی اطلاعات، ردهبندی است که با هدف تعیین محتوای موضوعی و شناسایی مفاهیم اصلی آثار، تخصیص شماره بازیابی، گروه بندی آثار هم موضوع و جایابی آثار از طریق شماره بازیابی انجام می شود که در نهایت در کتابخانه ها مورد استفاده کاربران قرار میگیرد. در واقع، ردهبندی باعث می شود که آثار هم موضوع کنار هم قرار گیرند و دسترسی به اطلاعات مرتبط افزایش یابد. به تعبیر دیگر، محتوای موضوعی آثار موجب می شود تا آثار فارغ از عنوان، نویسنده، قطع و اندازه در یک رده یا زیررده واحد کنار هم قرار گیرند.
در تدوین نظامهای رده بندی، کتابخانه ها از پیشگامان طراحی نظامهای فهرست نویسی و رده بندی برای منابع اطلاعاتی کتابخانه ای به شمار می روند. هدف اصلی فهرست نویسی و رده بندی، تسهیل دسترسی به اطلاعات مورد نیاز افراد در کوتاه ترین زمان ممکن است. نگاهی به تاریخ کتابخانه ها از دوران باستان تاکنون، نشان میدهد که کتابداران همواره در صدد یافتن راهی برای نظم دادن به مجموعه ها بوده اند تا دسترسی اثربخشی به محتوای منابع کتابخانه به عنوان یک پایگاه اطلاعاتی امکان پذیر باشد. به همین جهت در هر زمان با توجه به ویژگی های منابع کتابخانه و با استفاده از امکانات موجود، در مجموعه ها نظمی برقرار کرده اند تا از طریق آن، .دسترسی به مجموعه ها سریع تر و دقیق تر صورت گیرد
با ظهور منابع کتابخانه ای جدید، به معنای سازماندهی انواع بسیاری از اطلاعات و رسانه ها مورد توجه قرار گرفت، اطلاعاتی که در منابع فیزیکی مانند کتابها، نوارهای ویدیویی یا تصاویر ذخیره شده اند و سازماندهی اطلاعات مجازی یعنی اطلاعاتی که به صورت الکترونیکی در قالب کلمات، صداها یا تصاویر ذخیره شده اند و از طریق شبکه های رایانه ای قابل دسترسی میباشند (نوروزی و منصوری، ۱۳۸۵).
وب اکنون په عنوان یک منبع اطلاعاتی روزآمد و همیشه در دسترس در نظر گرفته می شود و به کتابخانه ای مبدل شده که دانش های بشری را به شکلی – الکترونیکی در خود گردآوری کرده است. اما مهم ترین و اصلی ترین تفاوت این به اصطلاح کتابخانه دیجیتالی بزرگ با کتابخانه های معمولی، در روند سازماندهی و رده بندی اطلاعات و اسناد موجود در آنها است؛ زیرا استانداردها و قوانین مدونی با – هدف گردآوری، سازماندهی، بازیابی و اشاعه اطلاعات و دانش در کتابخانه ها – تدوین گردیده که از جمله آنها میتوان به قوانین فهرست نویسی انگلو- امریکن یا رده بندی های ده دهی دیوئی و کنگره اشاره کرد، در حالی که یک چنین قوانین ،مشابهی برای اطلاعات و اسناد موجود در وب تدوین نشده اند (حسینی۱۳۸۵)
تاکنون دو شیوه رده بندی علوم و اطلاعات در جهان شکل گرفته است که عبارت انداز:
رده بندی کتابخانه ای
رده بندی کتابخانه ای نظامی برای طبقه بندی علوم گوناگون، سازماندهی و کدگذاری منابع کتابخانه ای (کتاب چاپی یا الکترونیکی، نشریه های ادواری چاپی یا الکترونیکی، مواد دیداری-شنیداری، فایلهای رایانه ای، نقشه ها، اسناد، نسخه های خطی و سایر منابع اطلاعاتی) براساس موضوع هر اثر است. به دیگر سخن «عمل سازماندهی جهان دانش به برخی نظم های نظام مند است». معروفترین نظام های رده بندی کتابخانه ای، رده بندی ده دهی دیویی و ردهبندی کتابخانه کنگره هستند که در رده های اصلی یا کلی به صورت سلسله مراتبی و شمارشی می باشند. نظامهای ردهبندی کتابخانه ای از «قواعد فهرست نویسی انگلو امریکن»، سرعنوان های موضوعی، طرح های رده بندی و جدول نشانه مؤلف سه رقمی کاتر-سن برن به منظور شماره سازی و تخصیص شماره ردهبندی به هر اثر استفاده می کنند.
مراحل فهرست نویسی و رده بندی مواد کتابخانه ای توسط متخصصان فهرست نویسی و رده بندی، کتابداران و نمایه سازان انجام می شود. کاربرد اصلی این نظام رده بندی، در سازماندهی مواد کتابخانه ای اعم از چاپی و غیر چاپی رسانه های سنتی اطلاعات است؛ ولی در سالهای اخیر به منظور سازماندهی سایر تی انجام گرفته است.
اختراع اینترنت و وب، نظام های رده بندی سنتی و کتابداران را با چالش های ویژه ای روبه رو ساخته است. با این وجود، کتابداران سعی کردهاند که از نظامهای منابع کتابخانه ای به ویژه منابع اینترنتی رده بندی کتابخانه ای به منظور سازماندهی منابع اطلاعاتی موجود در اینترنت و وب استفاده نمایند. مهم ترین راهنماهایی که توسط کتابداران یا براساس اصول رده بندی کتابداری طراحی شده اند، عبارتند از:
راهنمای BUBL ( www.bubl.ac.uk) راهنمای نظام رده بنای دهبالهی دیویی به منظور رده بندی منابع اینترنتی استفاده می کند. در واقع، یک خحد مت اطلاعاتی برای جامعه دانشگاهی انگلستان است و به همین دلیل منابع انگلیسی زبان را پوشش میدهد.
راهنمای آزاد www .dmoz .org. تقریباً جامع ترین راهنما برای وب است که توسط افراد از کشورهای مختلف داوری و طراحی شده است و از اصول کتابداری تا حدودی استفاده می کند.
راهنمایی یاهو (http://dir.yahoo.com): راهنمای وب است که توسط افراد از کشورهای مختلف داوری می شود و تا جدودی از اصول ردهبندی چهریزهای استفاده می کند.
نمایه کتابداران برای اینترنت (www.lii.org): توسط کتابداران آمریکایی طراحی و اداره میشود. به همین دلیل بیشتر منابع انگلیسی زبان و آمریکایی را پوشش میدهد.
کتابخانه عمومی اینترنت (www.ipl.org): یک خدمت اطلاعاتی عمومی است که توسط کتابداران دانشگاه میشیگان تهیه شده است و منابع انگلیسی زبان را پوشش میدهد(نوروزی و منصوری، ۱۳۸۵).
وبگاههای مهم مبتنی بر نظام فولکسونومی
وبگاههای مبتنی بر نظام فولکسونومی:
مهمترین وبگاهها خدمات اطلاعاتی که مبتنی بر نظام رده بندی مردمی هستند عبارت انداز:
- LibraryThing.com -LibraryThing هدف آن فهرست کاردن کتاب های . دلخواه کاربران است
- http://delicio.us- Del.icious هدف آن به اشتراک گذاشتن منابع وب وپیوندها میباشد
- www.citeulike.org – Citeulike هدف آن به اشتراک گذاشتن مشخصات کتاب شناختی و چکیده منابع و مقاله های علمی در وب است.
- connotea.org- Connotea به اشتراک گذاشتن دانش در.وب است
- www.flickr.com – Flickr هدف آن به اشتراک گذاشتن تصاویر میباشد.
- www.youtube.com – YouTube هدف آن به اشتراک گذاشتن آثار با موسیقایی و فیلم های کوتاه است.
- www.technorati.com – Technorati جستجو و بازیابی محتوای وبنوشت ها است.
- :(http://myweb.yahoo.com – МуWeb هدف آن به اشتراک گذاشتن وجست وجوی برچسب ها در موتور یاهو است.
سایر وب گاه های معروف مبتنی بر این نظام رده بندی عبارتند از:
Simpy.com, Frassle.org, Furl.net, Spurl.com
در زیر تصویری از یک جستجوی ساده در Del.icious برای بازیابی منابع مرتبط با فولکسونومی نشان داده میشود. همان گونه که قبلا گفته شد، در نظام رده بندی مردمی به راحتی می توان متوجه شد که چه کسانی و با چه کلیدواژه هایی یک منبع اطلاعاتی واحد را برچسبگذاری کرده و از طریق سایر کلیدواژهها یا برچسبها نیز میتوان به منابع مرتبط با موضوع جستجور دست یافت (نگاه شود به شکل ۱۱). به عنوان نمونه، منبع شماره یک در شکل زیر (مقاله انگلیسی در مورد مورد فوکسونومی در ویکیپدیا) توسط ۱۱۷۵ نفر برچسب گذاری شده است. به راحتی می توان متوجه شد که ۱۱۷۵ نفر دارای علائق مشابهی هستند و با چه کلیدواژه هایی این مقاله را برچسب گذاری کرد ه اند. همچنین میتوان فهمید که این مقاله محبوب ترین مقاله از نظر علاقه مندان به موضوع فولکسونومی است (نوروزی و منصوری،۱۳۸۵)
کاربرد «فولکسونومی» در بازنمون تصاویر دیجیتالی رویکردی نوین در نمایه سازی کاربرمدار
در این مقاله, روشهای نمایه سازی تصاویر که تا کنون مطرح بوده به اختصار بیان گردیده و نظری کلی از چالشهای مربوط به نمایه سازی تصویر مبتنی بر مفهوم, فراهم آمده است
در این مقاله، روشهای نمایهسازی تصاویر که تا کنون مطرح بوده به اختصار بیان گردیده و نظری کلی از چالشهای مربوط به نمایهسازی تصویر مبتنی بر مفهوم، فراهم آمده است. از روشی نوین با عنوان «فولکسونومی» یا «ردهبندی مردمی» که به میزان قابل ملاحظهای در دنیای کتابخانه دیجیتالی مورد توجه قرار گرفته است یاد میشود که در آن، برچسبزنی اجتماعی ابزاری برای افزایش توصیف اشیای دیجیتالی، فراهم کردن محملی برای درونداد کاربر و درگیری بیشتر کاربر، تلقی میگردد. این مقاله، به ارزیابی مزایا و معایب فرادادههای ساخته شده توسط کاربر در محتوای مجموعه تصاویر رقومی میپردازد و آن را با قالب فرادادهای ساخته شده به طور حرفهای و ابزار کنترل واژگان، مقایسه میکند. همچنین، ضمن تحلیل ویژگیهای ردهبندی مردمی، درمییابد که برچسبزنی مردمی میتواند به عنوان مکملی برای پیشینه های فرادادهای ساخته شده به طور حرفهای به مرحله عمل درآید تا فرصتی برای کاربر به منظور اظهار نظر درباره تصویر فراهم آید.
● مقدمه
تا پیش از آغاز جنگ جهانی دوم، مجموعههای عکس برای عموم قابل دسترس نبود و تنها پس از آن و در دوره بین سالهای ۱۹۳۰ تا ۱۹۶۰، شاهد افزایش مجموعههای تصاویر بودیم . در این زمان، به علت رشد مجموعه عکس، مشکل دسترسی موضوعی به تصاویر مطرح شد. در ابتدا مجموعه های عکس و بازیابی موضوعی آن مورد توجه افرادی غیر از کتابداران قرار گرفت. به طور مثال، «خن»[۲] [کوهن] از مؤسسه هنر شیکاگو، در مقالهای پیشنهاد میکند برای اسلایدها صفحه عنوانی مشابه آنچه در تک نگاشت ها وجود دارد در نظر گرفته شود (کرمی، نقل در مجله الکترونیکی نما،۱۳۸۵).
بعدها پیشنهاد شد یک تصویر باید در هر زمان از سه منظر «پیش پیکرنگاری»[۳]، «پیکرنگاری»[۴] و «شمایلشناسی»[۵] مورد توجه قرار گیرد. مثلاً در نمایهسازی تصویری از برج ایفل، پیشپیکرنگاری (برج، رودخانه، درخت) پیکرنگاری (برج ایفل، رودخانه سابن) واصطلاحات شمایلشناسی (خیال انگیزی، تعطیلات هیجان انگیز) را باید به این تصویر اختصاص داد (لنکستر[۶]، ۱۳۸۲ ،ص۱۹۲-۱۹۱).
در سال ۱۹۷۸ کنفرانسی با نام «منابع بصری» برپا شد که موضوع این کنفرانس دسترسی موضوعی به تصاویر بود. این کنفرانس مورد توجه محققان برجسته و متخصصانی قرار گرفت که در زمینه تصاویر کار میکردند. هدفها این کنفرانس در کنفرانس دیگری با نام «کنفرانس بلمونت» تداوم یافت. موضوع کنفرانس دوم که در سال ۱۹۸۰ تشکیل شد، دسترسی هوشمند به منابع بصری بود. شرکت کنندگان در این کنفرانس، ۹ نیاز یک سیستم پیکرنگاری را مطرح کردند و اشاره داشتند که این سیستم باید همه اصطلاحات مربوط به محتوا و مفهوم یک تصویر را در برگیرد. شرکتکنندگان بر این باور بودند که نمایهسازی موضوعی تصاویر بر پایه دو عنصر «مفهوم» و «محتوا» باشد. نمایهسازی مفهومی مسلماً محدودیتهایی دارد، زیرا تاحد زیادی انتزاعی و ذهنی است؛ بنابراین به آسانی قابل دستیابی نیست. افزون بر این، پیشبینی اینکه از یک تصویر در چه مواردی میتوان استفاده کرد، دشوار است (کرمی، نقل در مجله الکترونیکی نما، ۱۳۸۵).
گسترش فناوری دیجیتالی، دسترسی وسیع به منابع دیداری، که توسط کتابخانهها و موزهها نگهداری میشوند، را ممکن ساخته است. در دهه اخیر، مؤسسههای فرهنگی پروژههای دیجیتالی کردن در مقیاس گسترده را بر عهده گرفتهاند تا مجموعههایشان از عکسهای تاریخی و اسلایدهای هنری را به قالب دیجیتالی تبدیل کنند. تصاویر دیجیتالی شده از طریق مجموعههای دیجیتالی، با امکان کنترل بیشتر روی تصاویر و گزینههای متعدد جستجو، به کاربران روی وب ارائه میشود. پیشرفتها در حوزه سیستمهای نمایهسازی، بازیابی تصاویر و دستاوردها برای تعامل کاربر، با پیشرفتها در زمینه فناوری دیجیتالی و افزایش شمار مجموعههای تصویری همگام نبوده است (ترانت[۷]، ۲۰۰۳).
اخیراً وب فرصتی جدید برای اشتراک تصاویر دیجیتال و ردهبندی آنها به وسیله کلیدواژههای ساخته شده توسط کاربر به وجود آورده است. سایتهای حاوی عکس مثل flickr (www.flickr.com)، این امکان را فراهم میسازد که کاربران با استفاده از دایره اصطلاحات خود، تصاویر را بارگذاری و طبقهبندی کنند. نمایهسازی توسط کاربر که اغلب از آن به عنوان «فولکسونومی» یا «ردهبندی» مردمی یاد میشود، توجه قابل ملاحظهای به خود جلب کرد ه است تا آنجا که برخی از طرفدارانش آن را «انقلابی در طبقهبندی علوم و علوم انسانی» مینامند (استرلینگ[۸]، ۲۰۰۵ ص۲۱۳).
صحبت از انقلاب و دست کشیدن از استانداردهای فهرستنویسی و ابزار کنترل واژگانی، ممکن است کمی عجولانه به نظر برسد. از طرفی، ردهبندی مردمی موجب بحثی جدی در جامعه کتابخانه دیجیتالی درباره استفاده از کارکردهای اجتماعی شبکه، درگیر کردن کاربران و تشکیل انجمنهای مجازی گردیده است.
این مقاله ضمن بازنگری در پیشینه مربوط به نمایهسازی تصویر، نظرهایی کلی درباره «ردهبندی مردمی» را مطرح و چالشها و مزایای برچسبزنی مردمی و پیامدهای ضمنی بالقوه آن را برای فراهم کردن نمایهسازی کاربرمدار در مجموع تصاویر دیجیتالی بررسی میکند.
● رویکردها به نمایهسازی تصویر
در حال حاضر، از الگوهای مختلفی برای نمایهسازی تصاویر استفاده می شود که عبارتند از:
▪ رویکرد مبتنی بر محتوا
▪ رویکرد مبتنی بر متن
▪ رویکرد مبتنی بر ساختار
▪ رویکرد مبتنی بر مفهوم
رویکرد مبتنی بر محتوا، تصاویر را بر اساس ویژگیهای ذاتی و اولیه آنها نمایهسازی میکند، که به وسیله الگوریتمهای تحلیل تصویر متعدد پردازش میشوند. این ویژگیها شامل ساختار رنگ، خواص شکلی، بافت و … است.
بر اساس نمایهسازی مبتنی بر متن، چند شیوه برای بازیابی تصاویر وجود دارد:
– جستجوی کلیدواژهای با واژگان آزاد
– جستجوی کلیدواژهای با واژگان محدود
– جستجوی مبتنی بر اصطلاحنامه که در آن نه تنها واژگان محدود است، بلکه روابط سلسله مراتبی (اصطلاحات اعم و اخص) و سایر روابط میتوانند در فرایند جستجو مورد استفاده قرار گیرند.
ویژگی عمومی نمایهسازی مبتنی بر متن، این است که پرسش جستجو از مجموعهای از اصطلاحات همراه با روابط بولی شکل میگیرد و نمایه آن معمولاً شامل مجموعهای نامنظم از اصطلاحات است. دو فرایند «نمایهسازی» و «بازیابی» میتوانند به وسیله ابزارهایی (نرم افزارهایی) برای تورّق و انتخاب اصطلاحات از بانک واژگان پشتیبانی شوند.
رویکرد مبتنی بر ساختار، توصیفهای پیچیدهتری از جمله «روابط» را امکانپذیر میسازد. برای مثال، توصیفی از یک شیء عتیقه میتواند شامل توصیفی از اجزای تشکیلدهنده آن (برای مثال، کشوی یک جعبه) گردد. اجزای تشکیل دهنده، اشیایی هستند که می توانند با استفاده از ویژگیهایی مانند ماده، اندازه و شکل، توصیف شوند. اجزای تشکیل دهنده حتی میتوانند اجزایی تشکیل دهنده برای خود داشته باشند؛ مثلاً کشوها دستگیره دارند. رویکرد مبتنی بر ساختار، درجه گستردهای از پیچیدگی را در فرایند نمایهسازی ارائه میکند. توصیفات رابطهای میان طبقات مختلفی از اشیا، میتوانند تنوع گستردهای داشته باشند. یک راه حل برای مشکل پیچیدگی فرایند نمایهسازی، استفاده از اصطلاحات متنی (بافتی یا زمینهای) برای محدود کردن روابط و اصطلاحات ارائه شده به نمایهساز میباشد (ویلینگا[۹] ودیگران،۲۰۰۱).
نمایهسازی مبتنی بر مفهوم، دسترسی منطقی به محتوای دیداری یک تصویر را فراهم میکند. این نمایه شامل تبدیل اطلاعات دیداری به توصیف متنی به منظور بیان آنچه تصویر درباره آن است و آنچه را که نشان میدهد، میباشد. علاوه بر توصیف موضوعی، فرادادههای تخصیص داده شده به یک تصویر میتواند اطلاعاتی درباره مالک و منشأ تصویر را نیز دربر بگیرد. فرادادههای توصیفی بر اساس قالب فرادادهای استاندارد شدهای مثل Dubline core یا VRACore[۱۰] که از ابزار کنترل واژگانی و زبان طبیعی برای ارزیابی فرادادهها استفاده میکنند، ساخته شدهاند. نمایهسازی مبتنی بر مفهوم به جهت تفسیر معنایی عکس، تعیین سرعنوانهای موضوعی و بازنویسی حاشیه و برنوشتهای تصویر، همچون سه رویکرد فوق نیازمند نمایهساز انسانی است (ماتوزیاک[۱۱]،۲۰۰۶ ص۲۸۵).
فرایند تبدیل محتوای یک تصویر به عبارتهای زبانی، چالشهای* مهمی در نمایهسازی مبتنی بر مفهوم مطرح می کند که در ادامه بدانها میپردازیم.
برخی چالشها که به دلیل پیچیدگی و غنای رسانه دیداری به وجود آمدهاند، عبارتند از:
▪ تصاویر فراوانند و اغلب هر یک شامل اطلاعات مفیدی برای پژوهشگران در حوزه های مختلف می باشد .
▪ تصویر اغلب با هدفی استفاده میشود که توسط خالق آن پیشبینی نشده است.
▪ تصویر واحد میتواند معنای متفاوتی برای افراد متفاوت داشته باشد.
▪ تصاویر میتوانند لایههای متفاوت معنایی از تخصصی تا سطحی داشته باشند.
▪ برخلاف سند متنی، تصویر اطلاعاتی درباره مؤلف و خالقش ارائه نمیدهد.
▪ چالشهای دیگر در ارتباط با ابهامهای زبانی و محدودیتهای نمایهسازی توسط انسان:
▪ نبودِ توافق در خصوص ویژگیهایی از تصویر که باید نمایه شوند.
▪ دشواری تعیین عمق مناسبی از نمایهسازی.
▪ ذهنیت و هماهنگ نبودن نمایهسازانی که نمیتوانند اصطلاحات نمایه را با درجه واحدی از انسجام به کار ببرند.
▪ مشکل تطابق اصطلاحات استفاده شده توسط کاربران به منظور تشریح نیازهای اطلاعاتی آنان با واژگان کنترل شده در نمایهسازی.
▪ دشواری طراحی و تطابق مدل ذهنی کاربر از مفهوم تصویر با مدل ذهنی نمایهساز (ماتوزیاک، ۲۰۰۶. ص ۲۸۶-۲۸۵).
● مطالعات درباره کاربر
موفقیت یک کاربر در پیدا کردن تصاویر مورد علاقه، به کیفیت نمایهسازی تصویر و تطابق واژگان نمایهساز با زبان کاربر بستگی دارد؛ با وجود این، مطالعات بسیار اندکی در ارزیابی تأثیر نمایهسازی تصویر از منظر کاربر انجام گرفته است. مطالعات درباره کاربر عمدتاً روی گروههای خاصی متمرکز است و پرسشها در مجموعههای ویژه یا حوزههای موضوعی خاص، بررسی میشود. «آرمیتاژ»[۱۲] و «انسر»[۱۳] (۱۹۹۷) درخواستهای اعلام شده از هفت مرکز آرشیو تصویری را تجزیه و تحلیل کردند و آنها را مطابق با یک ماتریس سطحی[۱۴] و سه سطح از فشردگی طبقهبندی نمودند. آنها شباهتهایی در فرمول پرسش تصویر در مجموعهای از کتابخانههای مختلف مشاهده کردند (آرمیتاژ و انسر، ۱۹۹۷ ص۲۹۷).
«چویی»[۱۵] و «راسموسن»[۱۶] ( ۲۰۰۳) پرسشهای فرمول بندی شده توسط اعضای هیئت علمی و دانشآموختگانی که اطلاعات تصویری درباره تاریخ آمریکا را در مجموعه حافظه کتابخانه کنگره آمریکا جستجو می کردند، بررسی نمودند. مطالعه آنها نشان داد بیشتر نیازهای کاربر در زمره نیازهای عمومی قرار میگیرد، در حالی که تنها درصد کمی به مقولههای خاص تعلق دارد. پژوهشگران دریافتند توصیفگرهای موضوع، عنوان و تاریخ عوامل مهم در ارائه و جستجوی تصاویر هستند (چویی و راسموسن،۲۰۰۳ ص۵۰۹).
مطالعات بسیار اندکی از مشارکت کاربر در فرایند نمایهسازی یا درگیری کاربران، در توصیف تصاویر به عنوان بخشی از ارزیابی سیستمهای نمایهسازی انجام گرفته است. «هستینگز»[۱۷] (۱۹۹۹) پرسشهای کاربر، اصطلاحات تهیه شده توسط کاربر و اعمال بازیابی در مجموعه پیوسته نقاشیهای کارائیب معاصر را مقایسه کرد. در این تحقیق، از کاربران خواسته شد علاوه بر تهیه کلیدواژهها، اصطلاحات نمایهای تخصیص داده شده را رتبهبندی کنند. مطالعه «هستینگز» مشخص کرد کاربران نیاز دارند تا توصیفگرهایشان را با اصطلاحات نمایهای در فرایند جستجو ترکیب کنند (هستینگز، ۱۹۹۹، ص۴۵۰).
«یورگن سن» نیز در پژوهش خود از کاربران غیر متخصص خواست به توصیف تصویر بپردازند. وی روی انواع ویژگیهای تصویری و سطوح نمایهسازی تصویر تمرکز کرد. «یورگن سن» در مطالعه خود در سال ۱۹۹۸، تفاوتی بین ویژگیهای تصویری که کاربران توصیف میکنند و ویژگیهای مدنظر در سیستمهای نمایهسازی سنتی، مشاهده کرد. او توصیه کرد فرضیههایی در زمینه واژگان کنترل شده و ابزار توصیفی جدیدتر مانند قالب فرادادهای مطرح و مورد آزمون قرار گیرد (یورگن سن[۱۸]، ۱۹۹۸، ص۱۷۲).
● نیاز به رویکردی تازه
بررسی پیشینه پژوهش، نظر «هستینگز» (۱۹۹۹) را که میگوید «مشکل دسترسی منطقی به تصاویر در مجموعههای دیجیتال به طور عمده لاینحل باقی مانده است» منعکس میکند. این مشکل نیز نیاز به درگیری بیشتر کاربر در فرایند نمایهسازی و ارزیابی مهارتهای نمایهسازی از دیدگاه کاربر را مورد اشاره قرار میدهد. درعمل، کتابداران با شمار فزایندهای از تصاویر رقومی که برای بازیابی به صورت پیوسته به نمایهسازی نیازمندند، در کشمکش هستند. تسلط بر مهارتهای خاص نمایهسازی سنتی هزینه و نیروی انسانی زیادی میطلبد و حتی متخصصان نمایهساز مطمئن نیستند که بتوانند تنها روش یا بهترین روش را برای برآوردن نیاز کاربر فراهم میکنند. «ترانت» (۲۰۰۳) یادآور میشود، تفکری در میان کتابداران وجود دارد که کارهای بسیاری میتواند صورت گیرد تا دسترسی به مجموعههای دیداری، هم با استفاده از نمایهسازی موجود و هم با کاربردهای فناوریهای جدید، بهبود یابد. وی همچنین تشخیص داد که «با صحبت نکردن به زبان کاربران ممکن است با جامعه آنها بیگانه شویم». بسیاری از متخصصان نمایهسازی بر این باورند که مهارتهای نمایهسازی سنتی سندمدار برای نمایهسازی تصویر در محیط وب ناکافی است؛ از این رو رویکرد جدیدی را جستجو میکنند (ترانت،۲۰۰۳).
● ردهبندی مردمی
«ردهبندی مردمی» رویکردی جدید برای سازماندهی محتوایی محیط وب ارائه میکند که کاربران توصیفات متنیشان را با استفاده از اصطلاحات زبان طبیعی (tags) ساخته و آنها را با اجتماعی از کاربران به اشتراک می گذارند. این سیستمِ سازماندهی نوپا و در حال رشد که در آن کاربران کلیدواژهها را با مفهوم شخصی یا اشتراکی تخصیص میدهند، با عنوانهایی مانند «ردهبندی مردمی»، «ردهبندی توزیعی»[۱۹]، «برچسبزنی اجتماعی»، «ردهبندی قومی» و «فولکسونومی» نامگذاری شده است. اصطلاح folksonomy، مرکب از دو واژه folk و taxonomy، به «توماس واندروال»[۲۰] نسبت داده شده است. این ردهبندی از اقبال قابل توجهی برخوردار شده است. اما افرادی مانند «مرهولز»[۲۱] (۲۰۰۴) در مقالهای تحت عنوان «ردهبندی محلی و واژگان بومی» خاطرنشان میکند که اصطلاح فولکسونومی رایج نیست. تاکسونومی به یک ارتباط سلسله مراتبی اشاره میکند، در حالیکه فرایند برچسبزنی در نرمافزار شبکه اجتماعی، توسط ساختار غیرسلسله مراتبی و تکسطح توصیف میشود. اصطلاح ردهبندی مردمی در اینجا به منظور تأکید بر طبیعت مشارکتی برچسبهای ساخته شده توسط کاربران و استفاده آنها در متن اجتماع، استفاده شده است.
برچسبزنی مردمی در بسیاری از سرویسهای وبی معرفی شدهاند. کاربران میتوانند برچسبهای خود را در «جانمای»[۲۲] وبسایت (www.furl.net یا dil.icio.us)، «پیامهای وبلاگی»[۲۳] (Technorati.com)، و عکسها (www.flickr.com) تعیین کنند. [۲۴]CiteULike و [۲۵]connotea فرصتی برای برچسب زنی انتشارات دانشکده ای فراهم کرده اند. هدف از این برچسب زنی در این محیط اشتراکی، نه تنها برای سازماندهی محتوای وب برای یک کاربر، بلکه به منظور به اشتراک گذاشتن مقولهها با دیگر کاربران است، بنابراین آنها اطلاعات طبقهبندی شده توسط دیگران را میتوانند به سادگی تورق و بازیابی کنند. برچسبزنی اشتراکی زمانی بیشترین فایده را در بر دارد که هیچ فردی در نقش «کتابدار» برای ردهبندی اطلاعات وجود نداشته باشد، یا اینکه محتوای زیادی برای نمایهسازی موجود باشد (ماتوزیاک، ۲۰۰۶، ص۲۸۷).
● ردهبندی مردمی تصاویر رقومی
وبسایتهایی وجود دارند که برای کاربران، فضایی برای ذخیره عکسهای دیجیتالی فراهم میکنند. از جمله این سایتها Flickr میباشد. آنچه Flickr را منحصر به فرد و پرطرفدار ساخته ردهبندی و بهرهگیری شبکهای آن است که تعیین کردن برچسبها، اظهار نظر کردن و به اشتراک گذاشتن تصاویر و برچسبهای مرتبط را با اجتماعی از کاربران امکانپذیر میسازد. این سایت در فوریه ۲۰۰۴ راه اندازی شد.
تصاویر Flickr به دلیل اشتراکی که اخیراً با یاهو برقرار کرده است، به عنوان بخشی از جستجوی تصویر یاهو نیز میباشد. «اریک کاستلو»[۲۶]، یکی از توسعه دهندگان Flickr، طی مصاحبهای اظهار داشت Flickr ابتدا به عنوان ابزاری برای یک فرد تصور میشد تا مجموعه تصاویرش را سازماندهی کند و آنها را با استفاده از برچسبزنی ساده که روی جانمای سایت del.icio.us ساخته شده بود، با دوستان و خانواده به اشتراک بگذارد. اما در مدتی کوتاه، فشار برای ردهبندی و تعامل اجتماعی گستردهتر از سوی جامعه کاربران (کسانی که علاقهمند در به اشتراک گذاشتن عکسها و برچسبهایشان با جمعیت وسیعتری بودند نه فقط با مجموعه کوچکی از دوستان) وارد آمد.Flickr یک سیستم برچسبزنی ساده و بدون قید و شرط فراهم کرده است. کاربران میتوانند هر میزان برچسب که مایل باشند، با استفاده از کلیدواژههایی که معتقدند برای عکسها مناسبترین است، تخصیص دهند. آنها نیز فرصت این را دارند که ببینند دیگر کاربران چگونه برچسبها را در بافتار دیگر تصاویر به کار میبرند. این جنبه از بررسی جمعی یا بازخورد بیواسطه، آن چیزی است که ردهبندی مردمی را از نمایهسازی سنتی که معمولاً توسط نمایهساز و در نبود کاربر انجام میگیرد، متمایز میسازد. این حلقه بازخورد تنگاتنگ، به شکلگیری یک ارتباط نامتقارن بین کاربران از سوی فرادادهها منجر میشود. در کاربردهای شبکه اجتماعی، مثل Flickr معنی در همان بافتاری که مورد استفاده قرار گرفته، ساخته و دربار? آن توافق میشود (شاو[۲۷]،۲۰۰۶).
- عامترین برچسبهای Flickr در دهم ژانویه ۲۰۰۶
- نامهای خاص که محل جغرافیایی (Boston) را نشان میدهند، در کنار اصطلاحات موضوعی متناسب دیگر قرار گرفته اند. مانند bridge و building.
- ارتباطهای سلسه مراتبی وجود ندارد. Europe با Italy یا Rome در یک سطح قرار دارد.
- اسامی مفرد مانند animal، flower و dog با معادلهای جمع animals، flowers و dogs همراه هستند.
- کنترلی روی مترادفها وجود ندارد. newyork، newyork city و nyc در یک مجموعه قرار می گیرند.
- اصطلاحاتی مانند river یا rock با اصطلاحات انتزاعی تر مثل reflection آمده است.
- چندین برچسب مرکب وجود دارد که دو یا چند واژه را ترکیب میکند؛ مثل geotagging، black and white، road trip
- توصیفگرها مثل blue یا urban یا ضمایر (me) به سرعت به فهرست برچسبها اضافه می شوند.
- برخی از این ویژگیها مانند عدم کنترل مترادفها یا استفاده از مفرد و جمع، محدودیتهای ردهبندی مردمی با هدف بازیابی را نمایان میکند. برخی از پژوهشگران ماهیت به هم ریخته و درهم برهم برچسب زنی اجتماعی را بخصوص به هنگام مقایسه با سیستمهای ردهبندی مرسوم، یادآور میشوند (ماتوزیاک،۲۰۰۶ ص۲۸۹-۲۸۸).
«گای»[۲۸] و «تونکین»[۲۹] در مقالهای تازه، معایب اصلی فولکسونومی شامل غلطهای املایی، گروههای واژهای بد کدگذاری شده، قالب مفرد و جمع، برچسبهای شخصی و برچسبهای تک استفاده را تجزیه و تحلیل کردند. نویسندگان برخی استراتژیها را برای بهبود برچسبهای به هم ریخته پیشنهاد کردند، اما دریافتند که دشواری چنین عملیاتی ممکن است کاربران را دلسرد کند. برخی برچسبزنی را به عنوان روشی تدریجی از سازماندهی اطلاعات می دانند که مسیر خود را به سوی ناکامی طی میکند. اما همانطور که وب به ما نشان داده است، میتوانید مقدار شگفتانگیزی مطلب ارزشمند را از مجموعه دادههای درهم و برهم استخراج کنید (گای و تونکین، ۲۰۰۶ ص۱۷۳-۱۷۱).
«ردهبندی مردمی» دارای نقاط مثبت بویژه برای توصیف و بازیابی تصاویر میباشد. سیستم «هم ـ پیوندی»[۳۰] برچسبها، از فعالیتهای تورّقی و کشف اتفاقی تصاویر در محیط دیجیتالی حمایت میکند. مهمترین توانایی برچسب زنی اجتماعی، ارتباط نزدیک آن با کاربران و زبانشان می باشد. «میسز»[۳۱] (۲۰۰۴) خاطر نشان کرد، که برچسبزنی اجتماعی اختیارات کاربر در ترکیب کلمات، کاربرد اصطلاحات و صراحت را منعکس می کند. واژگان جاری و انعطافپذیر میباشند، ضمن اینکه سیستم، اصطلاحات و لغات ارائه شده توسط کاربران را به سرعت دربرمیگیرد. ترکیبات بینظم مترادفها، اختصارها، مفرد و جمعها حاکی از زبان طبیعی کاربران میباشد و این اصطلاحات شامل آنهایی است که کاربران هم برای توصیف تصویرشان استفاده میکنند و هم کلماتی است که آنها به احتمال زیاد به هنگام جستجوی تصاویر در دیگر مجموعههای دیجیتالی به کار خواهند برد (میسز، ۲۰۰۴).
● مشکلات اجرایی شدن برچسبزنی اجتماعی در مجموعههای تصویر رقومی
ردهبندی مردمی، تغییر مسیر مهم و امکاناتی جدید در زمینه نمایهسازی تصویر به وجود آورده است. اما راهحلی خارقالعاده یا ساده برای امور ذاتاً پیچیده در توصیف تصویر ارائه نمیکند. برعکس، گمان میرود چالشها و مشکلات دسترسی منطقی به تصاویر در محیط شبکه اجتماعی چندگانه باشد.
در بحث انگیزش نیز تفاوتی بنیانی بین ردهبندی مردمی و نمایهسازی سنتی وجود دارد. کاربران سایت Flickr محتویاتشان (مجموعههای عکس دیجیتالی شخصی که میخواهند مرتب کنند و با دوستان، خانواده و جامعه وسیعتری به اشتراک بگذارند) را برچسبگذاری میکنند. در محیط شبکه دیجیتالی، کاربران در راستای منافع خود اقدام به برچسبزنی میکنند. برخی افراد از این رویکرد در ردهبندی به عنوان برچسب زنی «خودپسندانه» یاد میکنند. پیشبینی اینکه آیا کاربران تمایل خواهند داشت تا تلاش و وقت خود را برای توصیف تصاویر موجود در کتابخانهها و موزهها بگذارند، مشکل است. برخی محققان نیز امور انگیزشی و پاداش را مطرح کردهاند. بحث درباره ردهبندی مردمی در مجموعههای دیجیتالی به سطح نظری باقی خواهد ماند، مگر اینکه اجرای کاربردهای شبکه اجتماعی را در سیستم کتابخانه دیجیتالی در مقیاس عظیمی شاهد باشیم. همچنین، کتابداران باید محیطی تشویق کننده ایجاد کنند تا کاربران به شرکت در فرایند نمایهسازی و در اختیار گذاشتن تخصص خود علاقهمند گردند (ماتوزیاک، ۲۰۰۶، ص۲۹۴).
● پیامدهای ضمنی برای مجموعه های تصویر دیجیتالی
اگرچه ردهبندی مردمی راهحلی جهانی نیست، امّا با طرح برخی چالشهای گذشته و جدید، فرصتهایی برای ارتقای نمایهسازی تصویر و درگیر کردن کاربران ارائه میکند. بسیاری از کتابداران احتمالاً نگرانند چنانچه نمایهسازی در اختیار کاربران قرار گیرد، نقش فهرستنویسان حرفهای چه خواهد شد؟ به طور جالب توجه اینکه، وقتی طراحی محیط رابط به سوی یک رویکرد کاربرمدارتر در حرکت بود، سؤالهایی مشابه توسط طراحان سیستم مطرح شده بود. به هرحال، طراحی محیط رابط با مشارکت کاربر و آزمون قابلیت استفاده، طراحان سیستم را بیکار نکرد.
الزاماً ردهبندی مردمی به عنوان جانشین نمایهسازی سنتی انگاشته نمیشود، بلکه ترجیحاًً به عنوان عاملی برای بهبود و تقویت نمایهسازی است. این دو رویکرد میتوانند مکمل یکدیگر باشند. با در نظر گرفتن مشکلات دسترسی منطقی به منابع دیداری، نمایهسازی سنتی، همسازی بیشتری در نمایهسازی و بطور نسبی سطح مشابهی از اخصّیت در توصیف ویژگیهای تصویر ارائه میکند. واژگان کنترل شده و استانداردها دسترسی یکنواخت و قابلیت درون کنشی[۳۲] را مقدور میسازند. در سوی دیگر، ردهبندی مردمی، موجب فراهمآوری زبان، دیدگاه و تخصص کاربر میشود و سرانجام ممکن است به نمایهسازی کاربرمدارتر منجر شود. بخصوص، فرصتهای فراوانی را برای درگیر شدن کاربر فراهم میکند.
در محیط کتابخانه رقومی کنونی، کاربران نه تنها مجاز به افزودن کلیدواژه در فرایند نمایهسازی نیستند، بلکه برای اظهارنظر کردن روی تصویر یا فراهم کردن بازخورد در نمایهسازی، فرصت اندکی، دارند. در نتیجه، مجموعههای تصویری دیجیتال در مقایسه با سایتهایی مثل Flickr تقریباً ایستا و یکدست ظاهر میشوند. «هیدورن»[۳۳] (۱۹۹۹) نمایهسازی را به عنوان شکلی از ارتباط بین نمایهساز و اشخاصی که تصاویر را در یک مجموعه جستجو میکنند، تلقی میکند. وی از میراث شناختی مشترک و زبان به عنوان عوامل اصلی ارتباط بین نمایهساز و پژوهشگر نام میبرد. در نمایهسازی سنتی سندمدار، این ارتباط یک سویه است. فهرستنویسان تعیین کننده ساختار و زبان توصیف هستند و کاربران در نهایت غیرفعال و دریافتکننده باقی میمانند. کاربردهای شبکه اجتماعی، اگر در مجموعه های دیجیتالی اجرا شود، ممکن است فرصتی برای مدل ارتباطی دوسویه فراهم کند (هیدورن، ۱۹۹۹، ص ۳۱۸-۳۱۶).
شکاف بین زبان کاربر و واژگان کنترل شده در نمایهسازی، مشکل اصلی در فراهم آوردن دسترسی منطقی به تصاویر، تشخیص داده شده است. واژگان کنترل شده، زبان کاربر را منعکس نمی کند و برای هدف نمایهسازی تصویر، ابزار انعطاف ناپذیر و منسوخ شده تلقی میگردد. برچسبهای ساخته شده توسط کاربر ـ گرچه بدون ساختار و بهم ریختهاند ـ غنیتر، رایجتر و چند زبانی میباشند. چندین راه برای یکپارچه کردن زبان کاربر در مجموعههای دیجیتال وجود دارد:
▪ کاربران میتوانند برچسبهای خود را به فرادادهها در رکوردها اضافه کنند.
▪ کاربران می توانند روی اصطلاحات تعیین شده توسط نمایه سازان بازخورد فراهم کنند.
▪ برچسبهای کاربران می تواند به منظور توسعه «واژگان کنترل شدهای که دقیقاً زبان کاربران را ادا میکند» مورد استفاده قرار بگیرد.
به علاوه، اجرا کردن کاربردهای شبکه اجتماعی در مجموعههای دیجیتالی میتواند طرح ایجاد دانش مشارکتی را در ذهن بپروراند.
کاربران میتوانند به عمق توصیف تصویر و افزایش محتوای منطقی مجموعههای دیجیتالی کمک کنند. درگیری کاربران میتواند موجب اقتباس شکلهای مختلفی از برچسبگذاریها، اظهار نظر کردن در مورد تصاویر و همچنین تفسیر آنها شود. تخصص در تاریخ و زبان محلی بویژه در مجموعههای میراث فرهنگی، میتواند ارزشمند باشد؛ جایی که کاربران می توانند با دانش و دیدگاه منحصر به فرد خود، به شناسایی تصاویر و افزایش توصیف کمک کنند. اظهار نظرهای کاربران نیز میتواند به عنوان دادههای باارزشی باشد که ارتباط مجموعهها با نیاز کاربران و فراهمآوری رهنمودهایی برای توسعه مجموعههای تصویر دیجیتالی در آینده را فراهم آورد (ماتوزیاک، ۲۰۰۶، ص۲۹۵).
● حاصل سخن
پدیده ردهبندی مردمی، پرسشهایی را درباره یک الگوی ثابت در فعالیت کتابخانهای کنونی، ـ جایی که نمایهسازی تصویر بدون حضور کاربران انجام میگیرد ـ مطرح کرده است. طراحی محیط رابط کاربرمدار در کتابخانههای رقومی، میزان قابل ملاحظهای از توجهات را به خود اختصاص داده است. اما نمایهسازی تصویر هنوز از اصول سنتی سندمدارانه پیروی میکند. صحبت از ردهبندی مردمی و «فراداده برای عامه مردم» شاید به شناخت زبان کاربر و دیدگاههای او به مجموعههای رقومی کمک کند که این خود به تأثیر متقابل بیشتر بین نمایهساز و کاربر و محیط کاربرمدار منتهی می شود. اگرچه ردهبندی مردمی به خودی خود پاسخی به بسیاری از مشکلات ذاتی در توصیف تصویر نیست؛ با این حال، میتواند به نمایهسازی کاربرمدارتر منتهی شود. از منظر یک متخصص شاغل در ساخت مجموعههای تصویری دیجیتال، این پدیده فرصتی را برای درگیری بیشتر کاربر و کمک به ایجاد جوامع مجازی فراهم میکند.
منابع
ـ کرمی، افسانه (۱۳۸۵). «نمایهسازی تصویردرپایگاههای اطلاعاتی». مجله الکترونیکی نما. شماره سوم،دوره ششم.
ـ لنکستر، اف دبلیو (۱۳۸۲). نمایهسازی و چکیدهنویسی. ترجمه عباس گیلوری. تهران: چاپار.
– Armitage, L.H and Enser, P.G.B.(۱۹۹۷),”Analysis of user need in image archives”,Journal of Information Science, Vol.۲۳ No.۴, pp.۲۸۷-۹۹.
– Choi, Y and Rasmussen, E.M. (۲۰۰۳), “Searching for images: the analysis of users` queries for image retrieval in American history”, Journal of the American Society for Information Science and Technology, Vol.۵۴ No.۶, pp.۴۹۸-۵۱۱.
– Guy, M. and Tonkin, E. (۲۰۰۶),” Folksonomies: tidying-up tags?”, D-Lib Magazine, Vol.۱۲ No.۱, [on-line] available: www.dlib.org/dlib/january۰۶/guy/۰۱guy.html
– Hastings, S.K. (۱۹۹۹), “Evaluation of image retrieval systems: rol of user feedback”, Library Trends, Vol.۴۸ No.۲, pp. ۴۳۸-۵۲.
– Heidorn, B.P. (۱۹۹۹),”Image retrieval as linguistic and nonlinguistic visual model matching”, Library Trends, Vol.۴۸ No.۲, pp.۳۰۳-۲۶.
– Jorgensen, C (۱۹۹۸), “Attributes of images in describing tasks”, Information Processing & Management, Vol.۳۴ Nos۲/۳, pp.۱۶۱-۷۴.
– Mathes, A. (۲۰۰۴), “Folksonomies – cooperative classification and communication through shared metadata”, [on-line] available: www.adammathes.com/academic/computer-mediated-communication /folksonomies. html (accessed October ۲۸,۲۰۰۵).
– Matusiak K., Krystyna.(۲۰۰۶), “Towards user-centered indexing in digital image collections”,OCLC Systems&Services: International digital library perspectives, Volume ۲۲ Number ۴ ۲۰۰۶ pp. ۲۸۳-۲۹۸.[on-line] available: www.emeraldinsight.com /۱۰۶۵-۰۷۵X.htm
– Merholz, P. (۲۰۰۴a), “Ethnoclassification and vernacular vocabularies”, Agust ۳۰, [on-line] available: www.peterme.com/ archives/۰۰۰۳۸۷.html
– Shaw,Blake.(۲۰۰۶),”Learning from a Visual Folksonmy: Automatically Annotating images from Flickr”. [on-line] available: http://www.metablake.com/vdb.final.pdf
– Sterling, B. (۲۰۰۵), “Order out of chaos”, Wired, Vol.۱۳ No.۲, p۲۰۰۵, [on-line] available: www.wired.com/wired/archive/۱۳.۰۴/ view.html?pg=۴ (accessed December ۲,۲۰۰۵).
– Trant, J. (۲۰۰۳), “Image retrieval benchmark database service: a needs assessment and preliminary development plan”, [on-line] available: www.clir.org/pubs/reports/ trant۰۴/tranttext.htm
– Wielinga, B. J. et al. (۲۰۰۱): “From Thesaurus to Ontology”. [on-line] available: http://www.cs.vu.nl/guus/ Papers/ Wielinga۰۱a. pdf
مجید سبزیپور دانشجوی کارشناسی ارشد علوم کتابداری واطلاع رسانی دانشگاه تهران sabzipoor۱۸۶۶@yahoo.com
۱. Kohn.
۲. Pre iconographic.
۳. Iconographic.
۴. Iconology.
۵. Lancaster.
۱. Ttrant.
۲. Sterling.
۱. Wielinga.
۲. (VRA): Visual Resource Association
۳. Matusiak
* این چالشها در مورد سه رویکرد دیگر نیز مطرحاند. اما به دلیل کاربرد بیشتر این رویکرد در حوزه نمایه سازی تصویر در این قسمت ذکر گردیده است.
۱. Armitage.
[۱۳] . Enser.
[۱۴] . Facet_based matrix.
[۱۵] . Choi.
[۱۶] . Rasmussen.
[۱۷] . Hastings.
۱. Jorgensen.
۱. Distributed classification.
۲. Thomas Vander Wal.
[۲۱]. Merholz.
۴. Bookmark.
۵. Weblog posts.
[۲۴]. http://www.citeulike.org.
[۲۵]. http://www.connotea.org.
۱. Eric Costello.
[۲۷] . Shaw
۱. Guy.
۲. Tonkin.
۳. Interlinked system.
۴. Mathes.
۱. Interoperability.
۱. Heidorn.
فولکسونومی چیست؟
فوکسونومی (Folksonomy ) عنوان تئوری جدیدی در رده بندی محتوای وب است که توسط توماس واندر وال، مطرح شده است. ( تعریف دائره المعارف ویکیپدیا از فوکسونومی ). این لغت در اصل از دو کلمه Folk (به معنای عامه ) و Taxonomy (یعنی رده بندی دانش ) مشتق شده است.
به طور خلاصه؛ فوکسونومی به روندی اطلاق می شود که طی آن فرمت های مختلف اطلاعاتی در وب اعم از متن، داده، صوت و تصویر در قالب کلیدواژه های معمولی و توسط کاربران عادی برچسب گذاری می گردند. این کلیدواژه ها که در اصطلاح فوکسونومی به آنها برچسب (tag ) گفته می شود امکان بازیابی و جستجوی منابع دانش، اطلاعات مختلف و پیوندهای وبی را برای همه کاربران فراهم می کنند. فوکسونومی با استفاده از مفاهیم جدیدی همچون Social Bookmarking ، Collaborative tagging، Social Software و با کمک فناوری های جدید نسل جدید و پویای وب، موسوم به وب 2، مانند RSS، AJAX و Tagging راه حلی جدید برای ساماندهی و رده بندی محتوای وب محسوب می شود.
نمونه های مشهور از فوکسونومی، عبارتند از Del.icio.us ( وب سایتی برای به اشتراک گذاری منابع و پیوندهای وبی ) ، Flickr ( وب سایتی برای به اشتراک گذاری و بازیابی تصاویر) ، Technorati ( وب سایتی برای جستجو و بازیابی محتوای وبلاگها ) ، Myweb2 یاهو ( سرویس به اشتراک گذاری و جستجوی تگ ها در موتور جستجوی یاهو ) ، Citeulike ( سرویس به اشتراک گذاری پیوندها به منابع و مقالات علمی در وب ) و Connotea (سرویس جستجو و به اشتراک گذاری دانش در وب ).
Taxonomy چیست؟

فولکسونومی – folk – Taxonomy
شاید قبل از اینکه با کلمه Taxonomy در مباحث IT آشنا شوید کاربرد این کلمه را در علم زیست شناسی دیده باشید وقتیکه با یک سر بریده و خشک شده گوزن با شاخهای بزرگ که به دیوار چسبیده مواجه می شوید. اما در حوزه IT مفهوم Taxonomy به علم معماری و طبقه بندی محتوا و داده های پایه در دسته های منطقی گفته می شود بطوریکه کاربران در برخورد با این ساختار به راحتی به اطلاعات مورد نظر دست پیدا کنند.
فرمول Taxonomy را می توان به شکل زیر نوشت:
معماری + ابزار + کارایی = Taxonomy
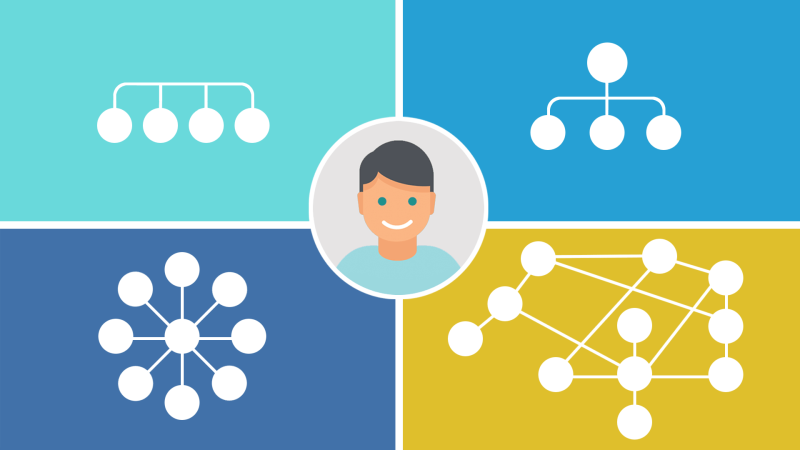
بطور کلی چهار مدل Taxonomy وجود دارد:
– مسطح (Flat)
– سلسله مراتبی (Hierarchical)
– شبکه ای (Networked)
– مفصلی (Faceted)
توجه داشته باشید که اشتباه در انتخاب نوع Taxonomy باعث شکست شما در کارتان خواهد شد.
در صورتیکه مجموعه آیتمهای مورد نیاز ما در معماری اطلاعات از عدد ۳۰ بالاتر نمی رود از این نوع تکسونومی استفاده خواهیم کرد. تکسونومی مسطح لیستی ساده از اقلام اطلاعاتی است.
خصوصیات تکسونومی مسطح
– محتویات در دسته های مشخص طبقه بندی می شوند.
– هیچ سلسله مراتب و ارتباطی بین دسته های تعریف شده وجود ندارد.
نمونه تکسونومی مسطح را می توان در سایتهای فروش الکترونیک بخوبی مشاهده کرد. در این سایتها دسته بندی های مشخصی از کالاها را در لیستی افقی از فروشگاه ها می توان دید.
کاربرد تکسونومی مسطح در Sharepoint در لیستها یا کتابخانه های اسناد (Document Libraries) است که تعداد زیادی آیتم در خود جای داده اند. برای یافتن اطلاعات مشخص می توان از امکانات Filtering در لیستها و همچنین Filter Web part و Viewها استفاده نمود.
تکسونومی سلسله مراتبی دارای ساختاری درختی است که شامل لینکها و اتصالات می باشد. در این مدل، مفاهیم بر اساس معانی خود به یکدیگر متصل می گردند. در این حالت این معانی هستند که ارتباط سلسله مراتبی را بر اساس جهت حرکت مشخص می نمایند. بعنوان مثال یخچال-> نوشیدنی -> آبمیوه -> آب پرتغال. ارتباط بین یخچال و نوشیدنی به معنی نوشیدنی است که در یخچال قرار دارد. تکسونومی سلسله مراتبی به معنی اعمال محدودیت است. یعنی در این مدل هر نود می تواند تنها یک منشاء (Parent) داشته باشد.
خصوصیات سلسله مراتبی
– سازماندهی محتوا حداقل در دو مرحله
– سلسله مراتب بصورت دوطرفه قابل دسترس می باشند
– هر مسیر حرکت معنی منحصر بفرد دارد
– حرکت به سمت منبع سلسله مراتب به معنی گسترش دسته بندی یا مفهوم است
– حرکت به سمت انتهای سلسله مراتب به معنی محدود نمودن دسته بندی یا مفهوم است
نمونه تکسونومی سلسله مراتبی وب سایتی است که دایرکتوری از موضوعات را در دسته بندی های بهم پیوسته ایجاد کرده است. در Sharepoint این نوع دسته بندی را در Site Collection های مختلف که بر اساس ساختار سازمانی ساخته می شوند می توان دید. در Sharepoint می توان سلسله مراتب را در سطوح مختلف پیاده نمود. سلسله مراتب دسترسی اطلاعات می توانند از سطح Site Collection ها ایجاد و تا صفحات و لیستها پایین بیایند.
در این مدل باید در نظر داشت که هر نود(node) باید دارای اطلاعات باشد و نودهای خالی برای کاربر بی معنی خواهد بود، بعلاوه هر نود باید یک دلیل موجه برای وجود در این ساختار داشته باشد. هر نود باید ارتباط مشخص با منبع و زیرمجموعه های خود داشته باشد.
در نظر داشته باشید که در پیاده سازی این مدل بهتر است بیش از چهار مرحله در سلسله مراتب پایین نروید.
تکسونومی شبکه ای
تکسونومی شبکه ای بطور نسبی دارای معماری نامشخصی است. در این مدل هر نود می تواند چند منبع و چند زیر مجموعه داشته باشد. به هر نود می توان از نودهای مختلف لینک برقرار کرد. هر لینک دارای وزن مشخصی است که نسبت ارتباط آن نود به نود دیگر را مشخص می کند.
خصوصیات تکسونومی شبکه ای
– محتویات به دو صورت سلسله مراتبی و ارتباط نظیر به نظیر طبقه بندی می شوند.
– تلفیق معماری ستاره ای و سلسله مراتبی
– هر دو نود در این مدل می توانند به هم لینک شوند.
– طبقه بندی ها و محتویات بر اساس وجوه اشتراک به یکدیگر لینک می شوند
– لینکها معنی کامل تری نسبت به آنچه در مدل سلسله مراتبی تعریف شد خواهند داشت.
در Sharepoint 2007 می توان برای کلمات قابل جستجو در سلسله مراتب مختلف مترادفهای متفاوت تعریف نمود و از این طریق نتایج جستجو را بهبود بخشید.
تکسونومی مفصلی
تکسونومی مفصلی مشابه یک گیاه است که که هر برگ آن به ساقه متصل شده است. در این مدل هر مفصل باید دلیلی مشخص برای وجود داشته باشد و هر جزء، باید رابطه مشخص و واضحی با منبع داشته باشد. بیشتر تکسونومی های مفصلی بر اساس جدولی از اطلاعات ساخته می شوند.
خصوصیات تکسونومی مفصلی
– هر مفصل می تواند توسط مقادیر یا ویژگیهای (Properties) مختلف توضیح داده شود
– هر مفصل می تواند جنبه های مختلف از یک موضوع را آشکار کند
– محتویات هر کدام از مقادیر یا ویژگیهای می تواند با دیگر مدلهای تکسونومی در ارتباط باشد
– معنی ساختار اصلی از مجموعه دسته بندی ها و موضوعات اصلی شکل می گیرد
بعنوان مثال Metadata می تواند نمونه ای از مفصل در تکسونومی مفصلی باشد. اطلاعات زیر می تواند بعنوان Metadata برای یک Object اطلاعاتی باشد:
– ایجاد کننده
– عنوان
– زبان
– تاریخ انتشار
– کلمات کلیدی
– موضوع
– سطح دسترسی
در Sharepoint هر گاه برای یک آیتم Metadata تعریف می کنیم از این مدل تکسونومی استفاده می نماییم. استفاده از Propertyهای مستندات Office بعنوان فیلدهای اطلاعاتی در Sharepoint نمونه استفاده از تکسونومی مفصلی است.
تعدادی از پروژههای مهم فولکسونومی:
Penntags: عنوان پروژه ای است که توسط دانشگاه پنسیلوانیا انجام گرفته و هدف آن مکان یابی، سازماندهی و اشتراک دادههای یافته شده در وب توسط کاربران است.کاربران میتوانند نشانی های اینترنتی نظیر پیوند به مقالات نشریات اطلاعات متنی و تصویری موجود در وب، و همچنین اطلاعات فهرست پیوسته آنلاین کتب و فهرست پیوسته فیلمهای کتابخانه دانشگاه را از طریق Penntags جمع آوری، و با یکدیگر به اشتراک گذارده، منابع و داده های گردآوری شده را با استفاده از تگ هایی که به آنها اختصاص می دهند سازماندهی و یا در قالب یک موضوع خاص، گروه بندی نمایند. به این ترتیب، دسترسی به منابع اطلاعاتی مورد نیاز نیز به راحتی میسر می شود. مهم ترین ویژگی این پروژه، امکان اشتراک دادههای بازیابی شده از فهرست های پیوسته کتب و فیلمهای موجود در کتابخانه دانشگاه توسط کاربران است.
KFTF: نام پروژه ای است که در حال حاضر در دانشکده علوم اطلاع رسانی دانشگاه واشنگتن انجام می شود. بر این مبنا، دادههایی که قبلاً توسط کاربران، بازیابی شده اند، گردآوری سازماندهی شده، امکان بازیابی مجدد آنها فراهم می گردد. این پروژه با هدف تقویت مهارت کاربران در «مدیریت اطلاعات شخصی»، و بازیابی اطلاعات در محیطهای الکترونیکی نظیروب و ایمیل صورت می گیرد.
H20 PLAYLIST: ابزاری برای یادگیری، آموزش و پژوهشی است که توسط دانشگاه هاروارد ابداع گردیده و طی آن، دانشجویان و محققان خواندنیها و منابع مطالعاتی خود را به اشتراک می گذارند. این ابزار، ضمن اینکه امکان اشاعه اطلاعات را از طریق سرویس خبر رسانی جاری و سیستم Alert، فراهم می آورد
Connotea : سرویس اشتراک اطلاعات و دانش Connotea» توسط گروه انتشاراتی nature راه اندازی شده است. این سرویسری کاربران را قادر می سازد منابع و مراجع اطلاعاتی خود در وب را نگهداری و سازماندهی کنند، و اطلاعات کتابشناختی مقالات و کتابهای خود را به اشتراک بگذارند. امکان جستجوی کلیدواژه های سایر کاربران و عضویت در گروه های موضوعی نیز وجود دارد. به نظر می رسد، فولکسونومی، با ایجاد رابطه تعاملی چندگانه بین داده و کاربر، علاوه بر ساده کردن روند سازماندهی محتوای وب، امکان بازیابی و اشاعه اطلاعات را نیز برای همه کاربران به آسانی فرآهم آورده است. در حقیقت فولکسونومی، ملیریت اطلاعات شخصی در محیط وب را به راحتی مقدور ساخته با بهره گیری از کلیدواژه هایی ساده، میسر نموده است. به علاوه، فولکسونومی، می چشمگیر کاربران اینترنت را به همراه داشته، به نحوی که در طی ماه های اخیر، تعداد سرویس های مبتنی بر فولکسونومی، چندین برابر شده اند و شرکتهای مهمی نیز که در امر جستجو در وب فعال هستند و به ارائه سرویس های مشابه مبادرت ورزیده اند، به طور مثال، سرویس جدید بلاگر، این امکان را به کاربر می دهد تا مطالب خود را برچسب گذاری نماید، یا امکان برچسب گذاری ایمیلها در سرویس پست الکترونیکی گوگل فراهم شده است، همچنین می توان از سرویس ہر جسبب گذاری اطلاعات در نوار ابزار گوگل” نام برد. در حال حاضر نیز، پژوهشهای عمده ای با هدف بررسی نقش و تأثیر فولکسونومی در بهبود بازیابی اطلاعات در محیطهای الکترونیکی و توسعه عناصر ابر داده ای و معناشناختی و انجام گرفته است. با این حال سازماندهی منابع اینترنت، همیشه در بین کتابداران متخصضان علوم اطلاع رسانی با چالش هایی مواجه بوده است و فولکسونومی نیز، به این چالش اضافه شده است. گرچه فولکسونومی توانسته است تا حدودی چشم استانداردهایی خاص برای این منظور تدوین نگردد، بحث ساماندهی اطلاعات وبی ،همچنان ادامه خواهد داشت (حسینی۱۳۸۵ )
